Sommaire
- ➔ CLI vs MCP : liberté d’expression contre contrat d’API
- ➔ Points de blocage techniques du MCP quand on sort des sentiers battus
- ➔ Automatisation avec LLM : serveur MCP dédié ou accès terminal, et risque d’“enfermement”
- ➔ Prêt à booster votre visibilité organique ?
- ➔ Pourquoi MCP est souvent perçu comme moins flexible : sécurité ou mur technique ?
- ➔ Critères techniques où le CLI restera plus performant (flux, interactivité, composition)
- ➔ Adapter des scripts DevOps en ressources MCP : difficultés sur enchaînements complexes et variables dynamiques
- ➔ Saturation sur gros volumes de logs : bande passante protocolaire ou sérialisation JSON ?
- ➔ Trois tâches d’admin système triviales en CLI mais pénibles à modéliser proprement en MCP
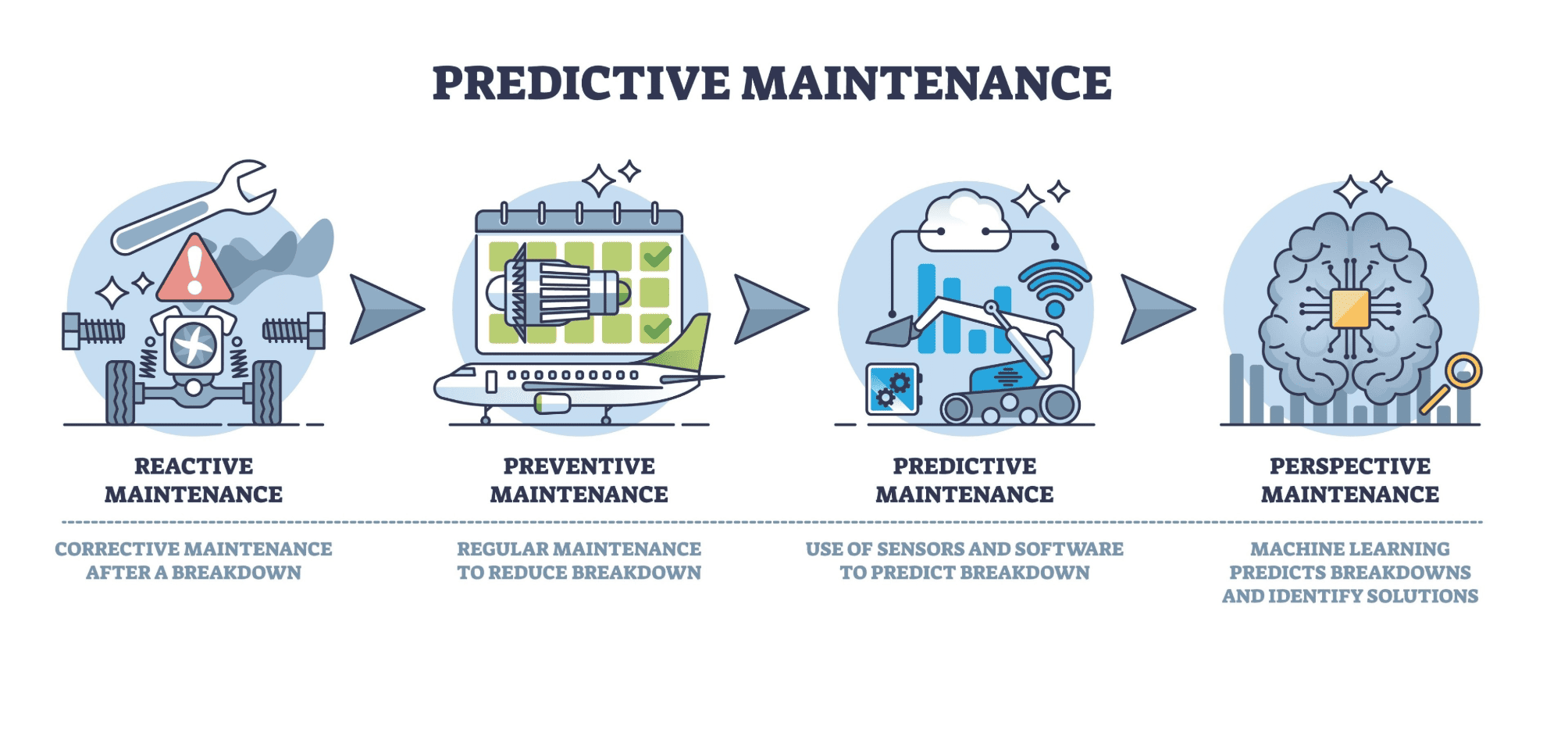
CLI vs MCP : liberté d’expression contre contrat d’API
Un script Bash “fait tout ce qu’on veut” parce qu’il s’appuie sur trois primitives extrêmement générales : exécuter un processus, chaîner des flux (stdin/stdout/stderr) et manipuler un environnement (variables, répertoire courant, droits, fichiers). La ligne de commande n’impose pas de schéma ni de typage : n’importe quelle commande peut produire n’importe quel texte, et le texte devient aussitôt une matière première pour la suivante via un pipe. Cette absence de contrat, qui est un défaut pour la robustesse, est précisément ce qui donne la sensation de liberté.
Le Model Context Protocol (MCP), lui, formalise l’accès à des capacités via des “tools” avec entrées/sorties structurées (souvent JSON) et des ressources. C’est un contrat. Ce contrat apporte de la testabilité, des garde-fous, une intégration plus propre avec un LLM, mais il réduit mécaniquement l’espace de ce qu’on peut improviser à la volée. La question “est-ce qu’on perd en liberté ?” se traduit techniquement par “est-ce que mes cas d’usage sont majoritairement des pipelines ad hoc et des manipulations de flux, ou des opérations bien définies et répétables qui méritent une API stable ?”.
Points de blocage techniques du MCP quand on sort des sentiers battus
Le premier blocage est l’écart entre un monde orienté flux (CLI) et un monde orienté messages (MCP). En CLI, un pipeline peut traiter des gigaoctets en streaming, avec backpressure implicite, sans jamais tout charger en mémoire. En MCP, la tentation naturelle est de renvoyer une réponse structurée complète, ce qui pousse vers des payloads volumineux, sérialisés, parfois bufferisés, et donc plus coûteux en CPU et en mémoire. Même si des implémentations peuvent “streamer”, la plupart des schémas de tools restent conçus pour des requêtes/réponses discrètes.
Le deuxième blocage est la combinatoire. En shell, tu combines arbitrairement des outils génériques (grep, awk, sed, jq, xargs, find) et tu obtiens un langage de composition. En MCP, la composition n’est pas “native” au protocole : elle existe via l’orchestration côté client (ton agent/LLM) ou via des tools plus gros qui encapsulent plusieurs étapes. Résultat : soit tu multiplies les tools très fins et tu te bats avec l’orchestration, soit tu fais des tools monolithiques et tu perds la modularité.
Le troisième blocage est l’expressivité implicite du shell : globbing, expansion, substitution de commande, redirections, here-doc, codes de retour, signaux, jobs en arrière-plan. Reproduire tout cela proprement dans des schémas MCP oblige à expliciter des détails qui, en CLI, sont gratuits. Le coût n’est pas seulement du développement ; c’est aussi un coût cognitif et un coût de surface d’API.
Automatisation avec LLM : serveur MCP dédié ou accès terminal, et risque d’“enfermement”
Donner un terminal à un LLM via un outil de code, c’est maximiser la flexibilité au prix d’un risque opérationnel élevé : commandes destructrices, exfiltration, dérives d’accès, difficulté à borner ce qui est autorisé. MCP, à l’inverse, te force à définir une frontière : quels outils, quels paramètres, quels chemins, quelles opérations. Le risque d’“enfermement” apparaît quand tu réalises que tes scripts internes sont un ensemble de “petites magies” contextuelles : dépendances implicites au répertoire courant, à des variables d’environnement, à un état local, à des formats de logs changeants, à des conventions d’équipe.
Concrètement, l’enfermement vient de trois rigidités : la rigidité du schéma (ce qui n’est pas prévu n’existe pas), la rigidité du modèle d’exécution (appel de tool plutôt que composition libre), et la rigidité de la gouvernance (chaque nouveau besoin devient une évolution d’API, donc revue, versioning, compatibilité). Si ton quotidien DevOps consiste à inventer des pipelines ponctuels, MCP te demandera de “produitiser” ces pipelines, ce qui peut être trop lourd.
Prêt à booster votre visibilité organique ?
Discutons de votre projet technique et définissons ensemble une stratégie sur-mesure.
Devis Audit SEOPourquoi MCP est souvent perçu comme moins flexible : sécurité ou mur technique ?
La sécurité et le sandboxing expliquent une partie de la perception : un terminal est dangereux, donc on le bride ; MCP est conçu pour être bridable par construction. Mais il existe aussi un mur technique : la ligne de commande est un environnement d’exécution universel (process model + flux octets), alors que MCP est un protocole d’intégration (messages structurés + outils déclarés). Le protocole n’est pas fait pour être un langage de composition de bas niveau ; il est fait pour exposer des capacités de façon contrôlée.
Le mur se voit dès que tu veux faire du traitement “à la volée” sur des streams : dans un shell, un pipe transporte des octets, et chaque commande peut être un filtre. Dans MCP, tu dois choisir entre transporter des données brutes (ce qui casse l’intérêt du schéma) ou transporter des structures (ce qui casse le streaming). Même quand tu fais du chunking, tu te retrouves à réinventer des protocoles de segmentation, reprise, ordering, et contrôle de flux au-dessus de JSON.
Critères techniques où le CLI restera plus performant (flux, interactivité, composition)
Pour décider si migrer vers MCP vaut le coup, il faut regarder où le CLI a un avantage structurel : traitement de gros volumes en streaming, latence minimale, et composition libre. Le CLI excelle aussi dans l’interactivité : TTY, curses, prompts, confirmations, visualisations, et outils qui adaptent leur sortie selon qu’ils parlent à un terminal ou à un pipe. MCP, lui, est meilleur quand tu veux des appels déterministes, auditables, et des retours structurés.
| Critère technique | Pourquoi le CLI garde l’avantage | Impact typique en MCP |
|---|---|---|
| Streaming massif (logs, traces, dumps) | Pipes octets, backpressure OS, zéro sérialisation structurée | Payloads JSON lourds, buffering, chunking à implémenter |
| Composition ad hoc | Chaînage libre de commandes, redirections, substitutions | Orchestration côté agent, explosion du nombre de tools ou tools monolithiques |
| Filtres textuels rapides | grep/awk/sed optimisés, traitement ligne à ligne | Transformation en structures puis filtrage, surcoûts CPU/mémoire |
| Interactivité TTY | Gestion native des prompts, couleurs, curseur, progress bars | Modélisation complexe, sorties “UI” peu naturelles en schéma tool |
| Gestion d’état implicite | cwd, env, droits, sockets, fichiers temporaires, exit codes | État à expliciter et transporter, risques d’incohérences |
| Performance sur petites opérations répétées | Coût d’appel faible, outils natifs, pas de sérialisation | Overhead protocolaire + JSON + validation de schéma |
| Compatibilité universelle | Tout système a un shell et des utilitaires standards | Dépendance à un serveur MCP, versions, déploiement, auth |
Adapter des scripts DevOps en ressources MCP : difficultés sur enchaînements complexes et variables dynamiques
Les scripts DevOps exploitent souvent des variables d’environnement dynamiques (CI, secrets injectés, contextes kube, profils cloud), des fichiers temporaires, et des conventions locales. En CLI, tu fais “export FOO=…; cmd1 | cmd2; if …; then …; fi” et tout l’état est dans le processus shell et ses enfants. En MCP, tu dois décider où vit l’état : côté serveur MCP (stateful) ou côté client (stateless). Un serveur stateful simplifie certains enchaînements mais complique la concurrence, la sécurité multi-tenant, et le nettoyage. Un serveur stateless force à passer explicitement l’état à chaque appel, ce qui alourdit les schémas et augmente les risques d’erreur.
Autre difficulté : les scripts reposent sur des codes de retour et des erreurs textuelles. MCP pousse vers des erreurs structurées, ce qui est bien, mais demande de normaliser une grande variété d’échecs (timeouts, permissions, ressources absentes, sorties partielles). Les enchaînements complexes qui dépendaient d’un “grep -q” ou d’un “|| true” doivent être re-exprimés en logique applicative. Tu gagnes en clarté, mais tu perds la concision et la capacité à bricoler vite.
Saturation sur gros volumes de logs : bande passante protocolaire ou sérialisation JSON ?
Dans la plupart des cas, ce n’est pas une “limite de bande passante” au sens réseau brut ; c’est un cumul d’overheads : sérialisation JSON (CPU), taille des messages (verbeux), encodage (parfois base64 si tu transportes du binaire), validation de schéma, et buffering. Un terminal/CLI traite des octets et peut afficher ou rediriger sans transformer la donnée. Un serveur MCP qui renvoie des logs en JSON va typiquement encapsuler chaque ligne, ajouter des champs, échapper des caractères, et produire des structures répétitives qui gonflent la taille.
Le symptôme “en CLI c’est instantané” vient aussi du streaming : “tail -f” affiche au fil de l’eau. Si ton tool MCP attend de finir une collecte avant de répondre, tu perds l’effet temps réel et tu augmentes la mémoire. Même avec du streaming, si tu streams des objets JSON ligne par ligne, tu restes plus lourd qu’un flux texte brut. La mitigation passe souvent par un design hybride : renvoyer un handle (ressource) vers un flux, paginer, compresser, ou fournir des filtres côté serveur pour réduire le volume avant transport. Mais ces mitigations te rapprochent d’un mini-système de logs, alors qu’en CLI tu avais déjà l’écosystème.
Trois tâches d’admin système triviales en CLI mais pénibles à modéliser proprement en MCP
1) Audit express de disque avec filtrage multi-étapes
En CLI, tu peux faire un diagnostic en une ligne : trouver les plus gros répertoires, exclure des chemins, trier, agréger, puis ouvrir un échantillon. C’est typiquement “du -x … | sort -h | tail …” combiné avec des exclusions. En MCP, soit tu exposes un tool “disk_usage_report” très spécifique (et tu ajoutes sans cesse des options), soit tu exposes des primitives (list files, stat, aggregate) et tu te retrouves à transférer des tonnes de métadonnées pour reconstituer le même tri côté client. Le problème n’est pas faisable vs infaisable ; c’est le coût de modélisation et le coût de transport.
2) Transformation de flux logs en temps réel avec corrélation
En CLI, “journalctl -f | grep | awk | sed” permet de filtrer en live, extraire un champ, corréler grossièrement, et produire une sortie exploitable immédiatement. En MCP, la corrélation “au fil de l’eau” impose un modèle de streaming robuste, une gestion de curseur, des reprises, et une notion de session. Si tu restes en requête/réponse, tu perds le temps réel. Si tu streams, tu dois définir comment le client consomme, s’arrête, reprend, et comment tu limites le volume.
3) Opérations conditionnelles rapides basées sur l’état local et des exit codes
Un classique DevOps : tester une condition, puis exécuter une action, sinon une autre, en s’appuyant sur le code de retour et l’état du système, par exemple “si le port répond, redémarre, sinon déploie”, ou “si le contexte kube est X, applique tel manifest”. En CLI, c’est immédiat parce que l’état (env, cwd, kubeconfig, credentials) est déjà dans le shell et les outils renvoient des exit codes standard. En MCP, tu dois expliciter le contexte (quel cluster, quels creds, quelle région, quel namespace), standardiser les erreurs, et éviter les ambiguïtés. Sans un modèle de contexte partagé très clair, tu multiplies les paramètres et tu fragilises l’ergonomie.
Tout sur le jargon SEO et GEO
Agent IA
Le terme “agent intelligent” recouvre un ensemble de fonctions qui, combinées, donnent l’impression d’un système capable de travailler comme un opérateur.
Duplication de contenu
Comprendre les risques du duplicate content interne et externe, et apprendre les solutions (canoniques, redirections) pour un SEO performant.
Domaine expiré
Comprendre le cycle de vie d’un nom de domaine et comment exploiter les domaines expirés pour booster votre SEO.