Sommaire
- ➔ Model Context Protocol (MCP) versus RAG : distinction fondamentale et logique d’architecture
- ➔ Mécanismes sous-jacents : comment ça marche, et où les implémentations divergent
- ➔ Quand privilégier RAG versus un protocole de contexte “standard” (sans RAG)
- ➔ Comparaison détaillée (critères techniques, risques, performances)
- ➔ Inconvénients majeurs et risques spécifiques
- ➔ Ressources nécessaires et impact performance : lequel est le plus “gourmand” ?
- ➔ Cas d’usage concrets : où MCP brille, où RAG est plus pertinent
- ➔ Comportement en scénarios complexes : forces et faiblesses pratiques
Model Context Protocol (MCP) versus RAG : distinction fondamentale et logique d’architecture
Un protocole de contexte pour modèle, typiquement le Model Context Protocol (MCP), répond à une question d’intégration : comment un modèle (LLM) découvre, appelle et consomme des ressources externes de manière standardisée, gouvernée et traçable. MCP se place au niveau “plomberie” entre l’application, le modèle et des services (outils, APIs, bases, dépôts, systèmes internes). Il définit des primitives d’échange de contexte et d’actions, avec des contrats d’interface, des schémas d’arguments, des permissions et une manière cohérente de présenter au modèle ce qu’il peut utiliser.
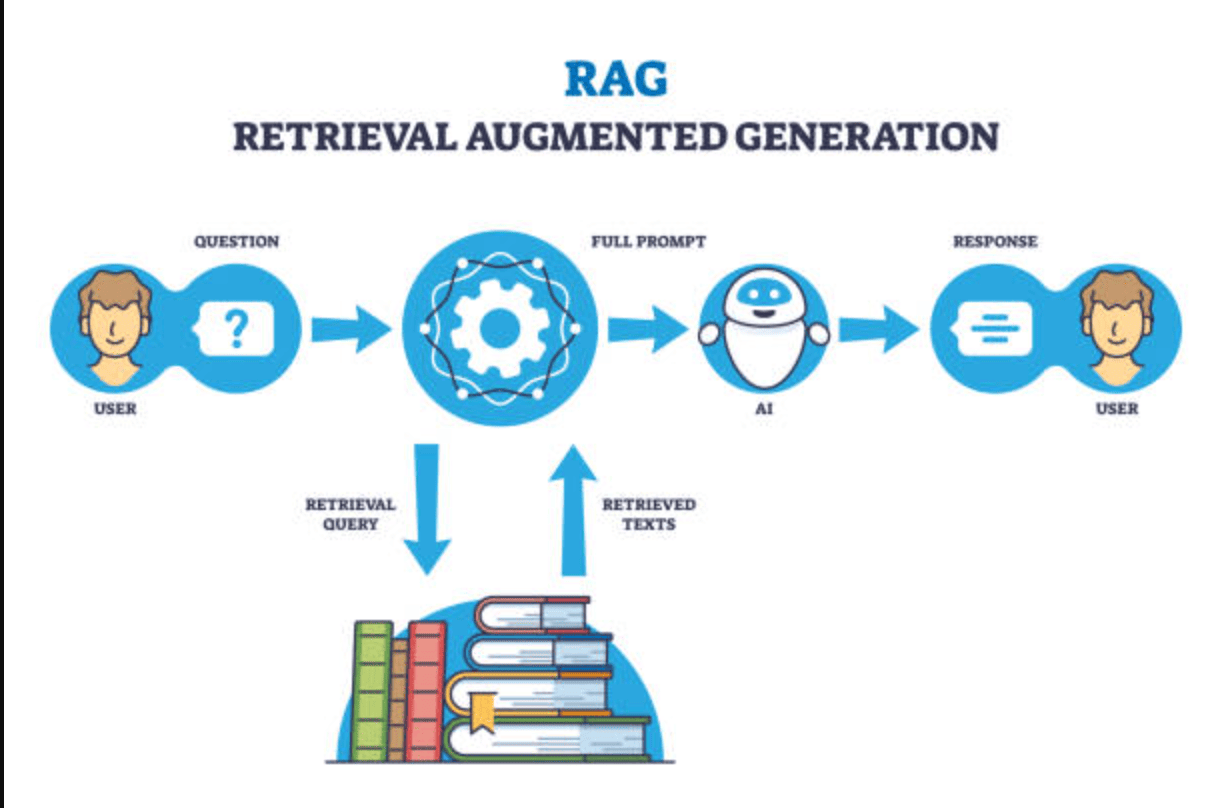
RAG (Retrieval-Augmented Generation) répond à une question de connaissance : comment fournir au modèle des informations pertinentes et à jour au moment de la requête en allant les récupérer dans un corpus (documents, pages, tickets, wiki), puis en les injectant dans le prompt. RAG est donc une architecture de recherche + sélection + génération. Elle ne normalise pas, en soi, l’accès aux outils ; elle ajoute une couche de retrieval (souvent via embeddings, recherche hybride ou BM25) et une étape d’assemblage de contexte (chunking, scoring, reranking, citations) avant la génération.
La différence clé est donc le “quoi” et le “comment” : MCP standardise la façon d’apporter du contexte et des capacités au modèle via des connecteurs/outils, tandis que RAG décrit une stratégie spécifique pour apporter de la connaissance textuelle pertinente via un pipeline de recherche. Dans la pratique, MCP peut transporter une implémentation de RAG comme un outil, et RAG peut fonctionner sans MCP, via une intégration ad hoc.
Mécanismes sous-jacents : comment ça marche, et où les implémentations divergent
Fonctionnement d’un protocole de contexte modèle (MCP)
Dans une approche MCP, on expose au modèle un ensemble de “capabilités” sous forme d’outils et de ressources. Un serveur MCP décrit ce qu’il sait faire et comment l’appeler (schémas d’entrées/sorties, descriptions, contraintes). L’application ou l’orchestrateur autorise certains outils selon le contexte (identité utilisateur, environnement, politique de sécurité). Le modèle, lorsqu’il doit accomplir une tâche, peut demander l’usage d’un outil ; l’orchestrateur exécute l’appel réel, récupère le résultat, puis le réinjecte dans le contexte du modèle. L’implémentation diverge surtout sur la gouvernance : gestion des secrets, isolation réseau, audit, quotas, filtrage des données, et “tool choice” (règles, modèles spécialisés, guardrails) qui déterminent quand et comment les outils sont appelés.
Fonctionnement d’une architecture RAG
RAG se décompose en deux temps. En amont, l’ingestion : on collecte les sources, on les nettoie, on les découpe en segments (chunking), on calcule des représentations (embeddings) et on indexe (vector store, recherche hybride, métadonnées). À la requête, on reformule ou on enrichit la question, on récupère les passages candidats (top-k), on rerank, on assemble un contexte (souvent avec des contraintes de taille), puis le modèle génère une réponse en s’appuyant sur ces extraits. Les divergences d’implémentation se situent dans la qualité du chunking, le choix des embeddings, l’indexation (hybride vs vector pure), la stratégie de reranking, la gestion des métadonnées, la fraîcheur des données, et la manière de forcer l’usage des sources (citations, vérification, refus si sources insuffisantes).
Le point d’intersection pratique est important : RAG produit du contexte textuel ; MCP fournit un canal standard pour obtenir ce contexte via un outil de recherche, ou pour appeler un service de retrieval interne. Mais MCP n’impose pas un retrieval vectoriel, et RAG n’impose pas un protocole standard d’outillage.
Quand privilégier RAG versus un protocole de contexte “standard” (sans RAG)
RAG est à privilégier lorsque le besoin principal est la précision factuelle sur un corpus volumineux et changeant, et lorsque la réponse doit être justifiable par des sources. Typiquement, dès que vous avez des milliers de documents, des mises à jour fréquentes, ou des exigences de traçabilité (citations, conformité), RAG devient l’architecture la plus directe pour réduire les hallucinations et améliorer la couverture des connaissances hors entraînement.
Un protocole de contexte modèle “standard” (MCP) est à privilégier lorsque le besoin principal est l’intégration fiable à des systèmes et outils, avec une surface d’attaque maîtrisée et une standardisation des connecteurs. Si votre valeur vient de l’action (créer un ticket, déclencher un pipeline, lire un CRM, exécuter une requête SQL contrôlée) plutôt que de la synthèse d’un grand corpus documentaire, MCP apporte de la robustesse opérationnelle. Dans ce cas, le contexte pertinent n’est pas forcément un long texte récupéré, mais des données structurées et des résultats d’outils.
Dans une feuille de route réaliste, on choisit souvent MCP pour industrialiser l’accès aux outils, puis on ajoute RAG comme l’un de ces outils lorsque la connaissance documentaire devient un goulot d’étranglement. L’inverse est également fréquent : un POC RAG fonctionne vite, puis on “durcit” l’intégration via MCP pour la sécurité, la gouvernance et la maintenabilité.
Comparaison détaillée (critères techniques, risques, performances)
| Critère | Model Context Protocol (MCP) | RAG (Retrieval-Augmented Generation) |
|---|---|---|
| Nature | Protocole/standard d’intégration entre LLM et ressources/outils | Architecture de recherche + injection de contexte + génération |
| Objectif principal | Accès gouverné, standardisé et traçable à des capacités externes | Améliorer la factualité et la couverture via récupération de documents |
| Type de “contexte” fourni | Résultats d’outils, données structurées, extraits, états applicatifs | Passages textuels pertinents (chunks) issus d’un corpus indexé |
| Implémentation typique | Serveurs d’outils, schémas d’appels, permissions, orchestration, audit | Ingestion, chunking, embeddings, index (vector/hybride), reranking |
| Gouvernance & sécurité | Très forte : contrôle des outils, isolation, secrets, politiques d’accès | Variable : dépend de l’implémentation (filtrage, ACL, contrôle d’accès) |
| Risques majeurs | Tool misuse, injection via outils, escalade de privilèges, fuites via logs | Récupération hors sujet, fuites de données (mauvais ACL), citations trompeuses |
| Latence | Dépend du nombre d’appels outils et de leurs temps de réponse | Dépend du retrieval (top-k, rerank) + taille du contexte injecté |
| Coûts de calcul | Coûts liés aux appels externes et à l’orchestration (variable) | Coûts d’ingestion (offline) + requêtes vectorielles/reranking (online) |
| Scalabilité | Bonne si outils stateless et bien quotas; complexité d’observabilité multi-outils | Bonne si index optimisé; attention au volume, au reranking et à la fraîcheur |
| Meilleur fit | Assistants “opérationnels” orientés actions et données structurées | Assistants “connaissance” orientés Q/R documentaire et support |
| Complémentarité | Peut encapsuler RAG comme outil standardisé | Peut fonctionner sans protocole, mais gagne en robustesse avec MCP |
Inconvénients majeurs et risques spécifiques
Risques et limites côté MCP
Le premier risque est l’extension de la surface d’attaque : plus vous exposez d’outils, plus vous créez de chemins potentiels pour des actions non désirées, surtout en présence d’injections de prompt qui poussent le modèle à appeler des outils. La mitigation passe par des politiques d’autorisation strictes, une séparation des rôles, des validations côté serveur (ne jamais faire confiance au modèle), et des garde-fous sur les paramètres (whitelists, requêtes SQL paramétrées, limites de périmètre).
Le second risque est la complexité opérationnelle : observabilité des appels, gestion des erreurs, timeouts, retries, cohérence transactionnelle et idempotence. Un assistant qui enchaîne plusieurs outils peut échouer partiellement ; sans conception robuste, vous obtenez des états incohérents (exemple : ticket créé mais réponse finale échoue). Enfin, MCP ne “résout” pas la connaissance : si le modèle a besoin d’un corpus documentaire, MCP doit s’appuyer sur un outil de recherche, sinon il reste limité à ce que l’application lui fournit.
Risques et limites côté RAG
RAG échoue souvent de manière silencieuse : si le retrieval renvoie des passages non pertinents, le modèle peut produire une réponse plausible mais fausse, en s’appuyant sur un contexte bruité. La qualité dépend fortement du chunking, des métadonnées, du scoring et du reranking. Un autre risque est la sécurité des données : si l’index n’applique pas strictement les ACL, un utilisateur peut obtenir des extraits qu’il ne devrait pas voir. Les fuites peuvent être aggravées par la mise en cache, les logs, ou la persistance des prompts.
RAG introduit aussi des coûts de maintenance : ingestion continue, déduplication, gestion des versions, suppression (droit à l’oubli), et évaluation régulière (golden set) pour éviter les régressions. Enfin, RAG peut être fragile sur les questions nécessitant des calculs, des jointures complexes ou des actions ; il excelle sur l’accès à du texte, moins sur l’exécution contrôlée de processus métier.
Ressources nécessaires et impact performance : lequel est le plus “gourmand” ?
Il n’y a pas de vainqueur universel, car la gourmandise dépend du profil de requête. RAG consomme des ressources en deux phases : une phase offline (ingestion, embeddings, indexation) qui peut être lourde mais amortie, et une phase online (recherche + reranking + tokens supplémentaires) qui ajoute de la latence et augmente la taille du prompt. Si vous injectez beaucoup de texte, vous payez en tokens et en temps de génération, et vous risquez de diluer l’attention du modèle.
MCP déplace le coût vers les appels outils. Une requête peut être peu coûteuse si elle déclenche un seul appel rapide (exemple : lecture d’un enregistrement), ou très coûteuse si elle orchestre plusieurs systèmes lents (CRM, ERP, data warehouse). En performance, MCP est surtout sensible aux temps réseau, aux limites de débit, et à la sérialisation des appels. En coût LLM, MCP peut être plus léger que RAG si les outils renvoient des résultats structurés et compacts plutôt que de longs extraits textuels.
En pratique, RAG devient plus gourmand lorsque le corpus est vaste, que le top-k est élevé, que le reranking est sophistiqué, ou que les réponses exigent beaucoup de citations. MCP devient plus gourmand lorsque l’assistant doit “agir” en multipliant les appels, ou lorsque les outils sont eux-mêmes coûteux (requêtes analytiques, exécutions de jobs).
Cas d’usage concrets : où MCP brille, où RAG est plus pertinent
Cas où MCP apporte un avantage net
Dans un assistant ITSM, MCP est particulièrement efficace pour standardiser la création de tickets, la consultation d’incidents, la lecture de métriques et l’exécution d’actions contrôlées (redémarrage, déploiement, rotation de logs) via des outils explicitement autorisés. Dans un contexte CRM/ERP, MCP permet d’exposer des opérations métier (rechercher un client, générer un devis, vérifier un stock) avec des schémas d’arguments stricts et des validations serveur. Dans un environnement réglementé, MCP facilite l’audit des appels, le cloisonnement des données et la gestion des secrets, car l’accès passe par des connecteurs gouvernés plutôt que par du texte libre.
Cas où RAG est la solution la plus pertinente
Pour un support client basé sur une base de connaissance, RAG excelle à retrouver la procédure exacte, la version à jour et les notes de compatibilité, puis à synthétiser une réponse contextualisée. En juridique interne, RAG permet de naviguer dans des contrats, politiques et jurisprudences internes, en fournissant des extraits citables. En ingénierie, RAG est performant pour interroger des RFC, ADR, docs d’API et runbooks, surtout lorsque la documentation change souvent et que la “vérité” est dans les documents, pas dans des systèmes transactionnels.
Comportement en scénarios complexes : forces et faiblesses pratiques
Dans un scénario complexe de bout en bout, par exemple “diagnostiquer un incident et proposer un correctif”, RAG et MCP se complètent mais ne se substituent pas. RAG apporte la mémoire documentaire : historiques d’incidents, post-mortems, runbooks, et contraintes de versions. MCP apporte l’exécution et la vérification : interroger l’observabilité, vérifier l’état réel des services, appliquer un changement, puis confirmer le résultat. Sans RAG, l’assistant peut ignorer des procédures critiques ; sans MCP, il peut produire une recommandation non vérifiée et non actionnable.
Sur des tâches multi-étapes, MCP est fort quand les étapes sont des opérations bien définies, contrôlables et vérifiables. Sa faiblesse apparaît lorsque l’information nécessaire est diffuse dans des documents et nécessite une recherche sémantique. RAG est fort pour rassembler des éléments textuels dispersés et fournir une base factuelle, mais il est faible si la question exige une exécution déterministe, des contraintes transactionnelles, ou une preuve d’état “en temps réel”.
Enfin, les deux approches partagent un problème : l’orchestration. Dans la pratique, vous devez gérer la sélection des bons outils (MCP) ou des bons documents (RAG), la gestion des erreurs, la limitation des coûts, et l’évaluation. La différence est que MCP formalise davantage l’intégration et la gouvernance, tandis que RAG formalise davantage la chaîne de retrieval et la qualité du contexte injecté.
Tout sur le jargon SEO et GEO
UI (User Interface)
Tout sur le design d’interface utilisateur : comment les éléments graphiques influencent votre site.
Codex (Open IA)
Codex est l'outil de Open IA dédié à la programmation, capable de générer, déboguer et analyser du code complexe en Python, JS et bien d'autres.
Moteur de recherche
Le cœur du web : comment Google et ses alternatives indexent et classent l’information mondiale.
Dominez les moteurs de recherche IA (GEO)
Anticipez le futur de la recherche. Optimisez votre contenu pour apparaître dans les réponses de Gemini, ChatGPT et Perplexity.
Découvrir mes services

